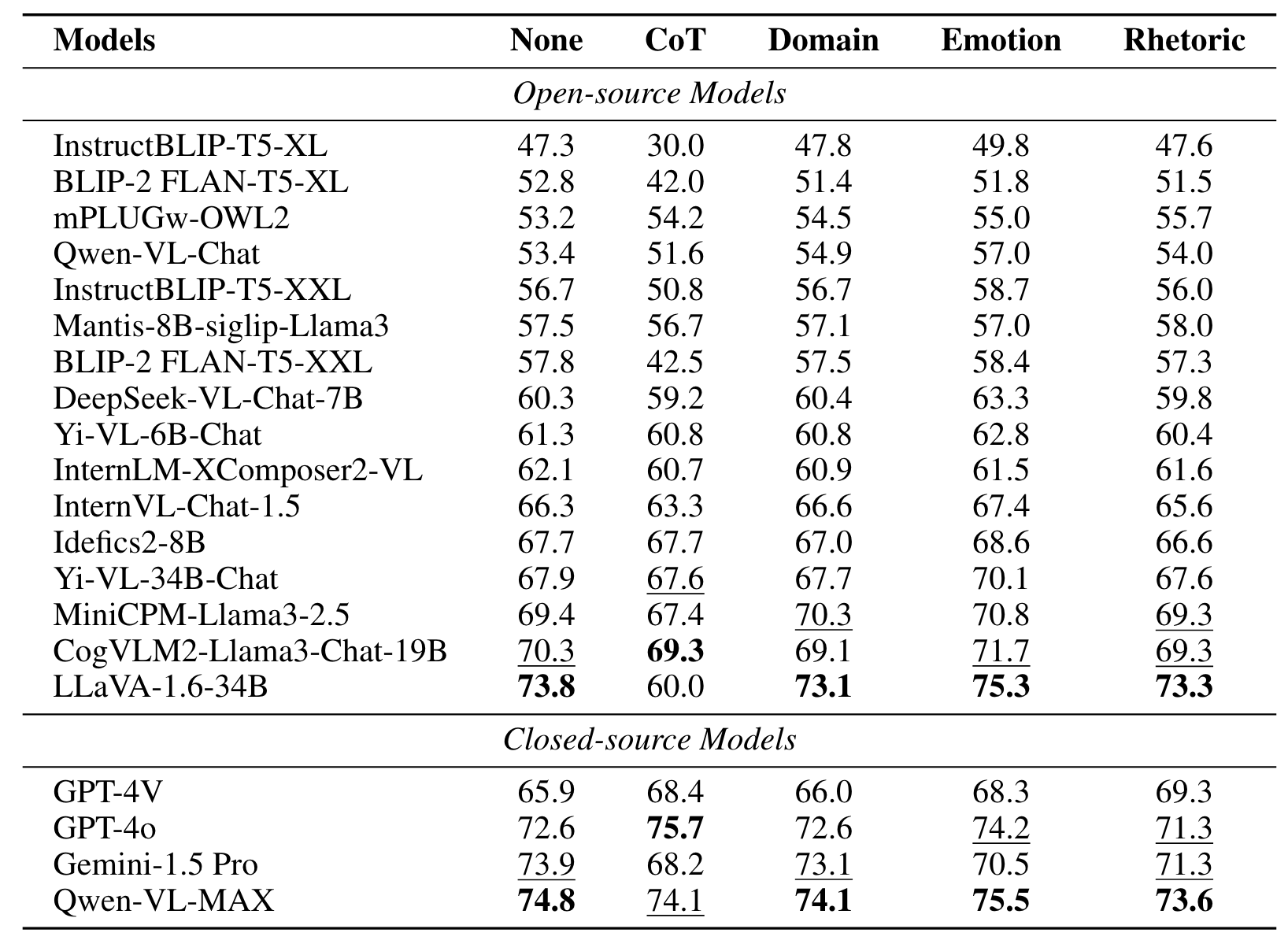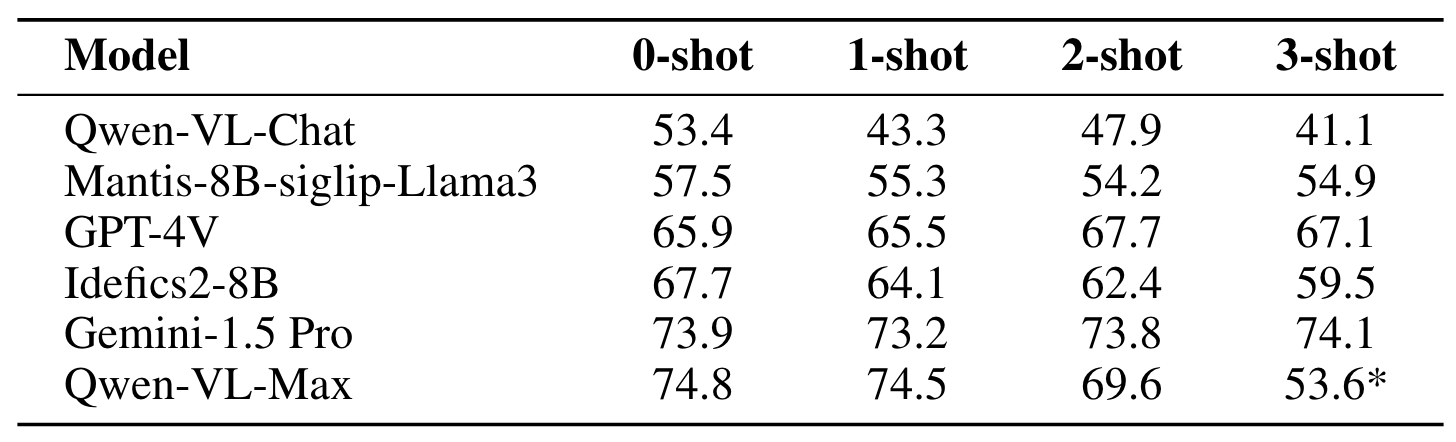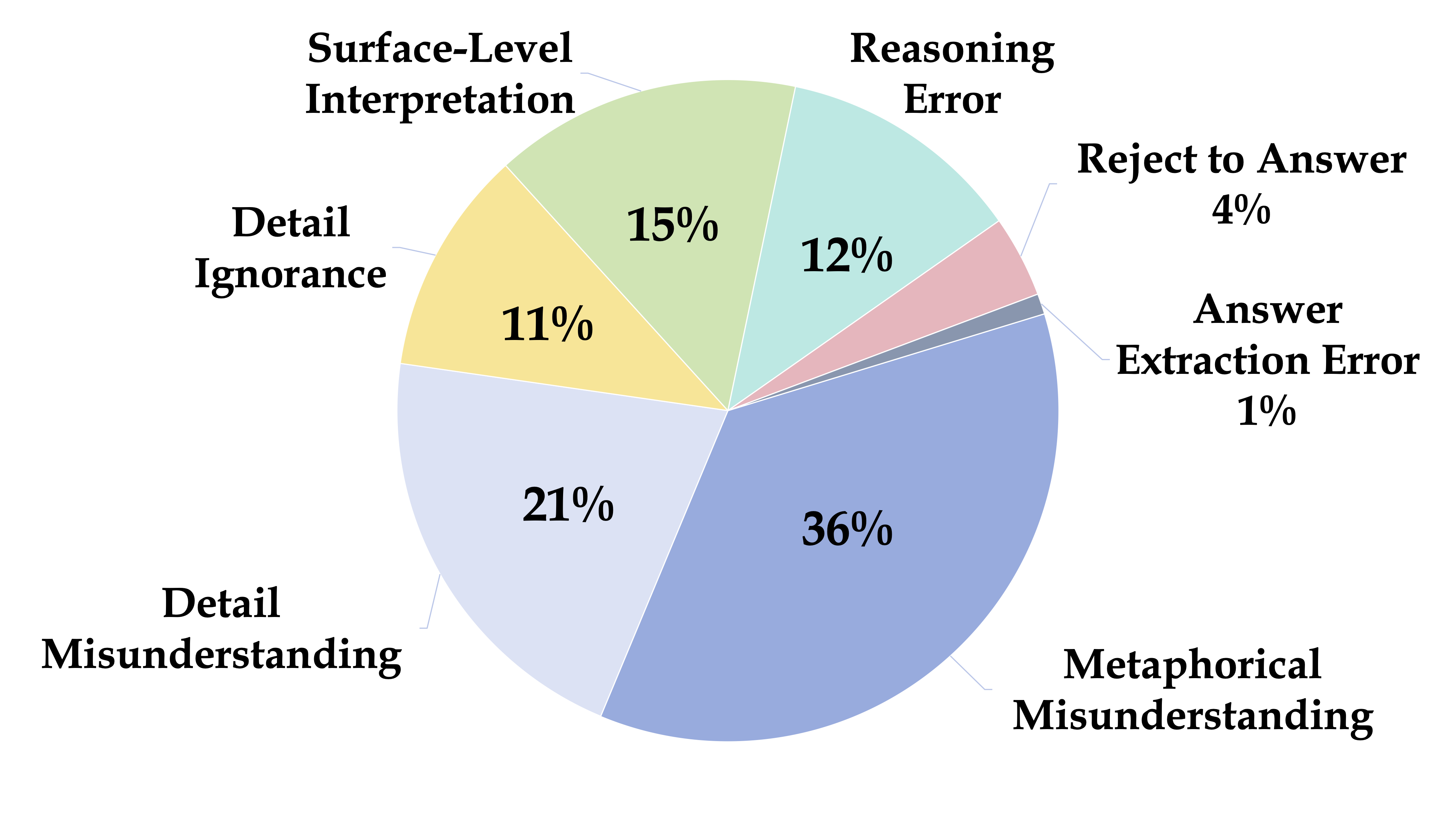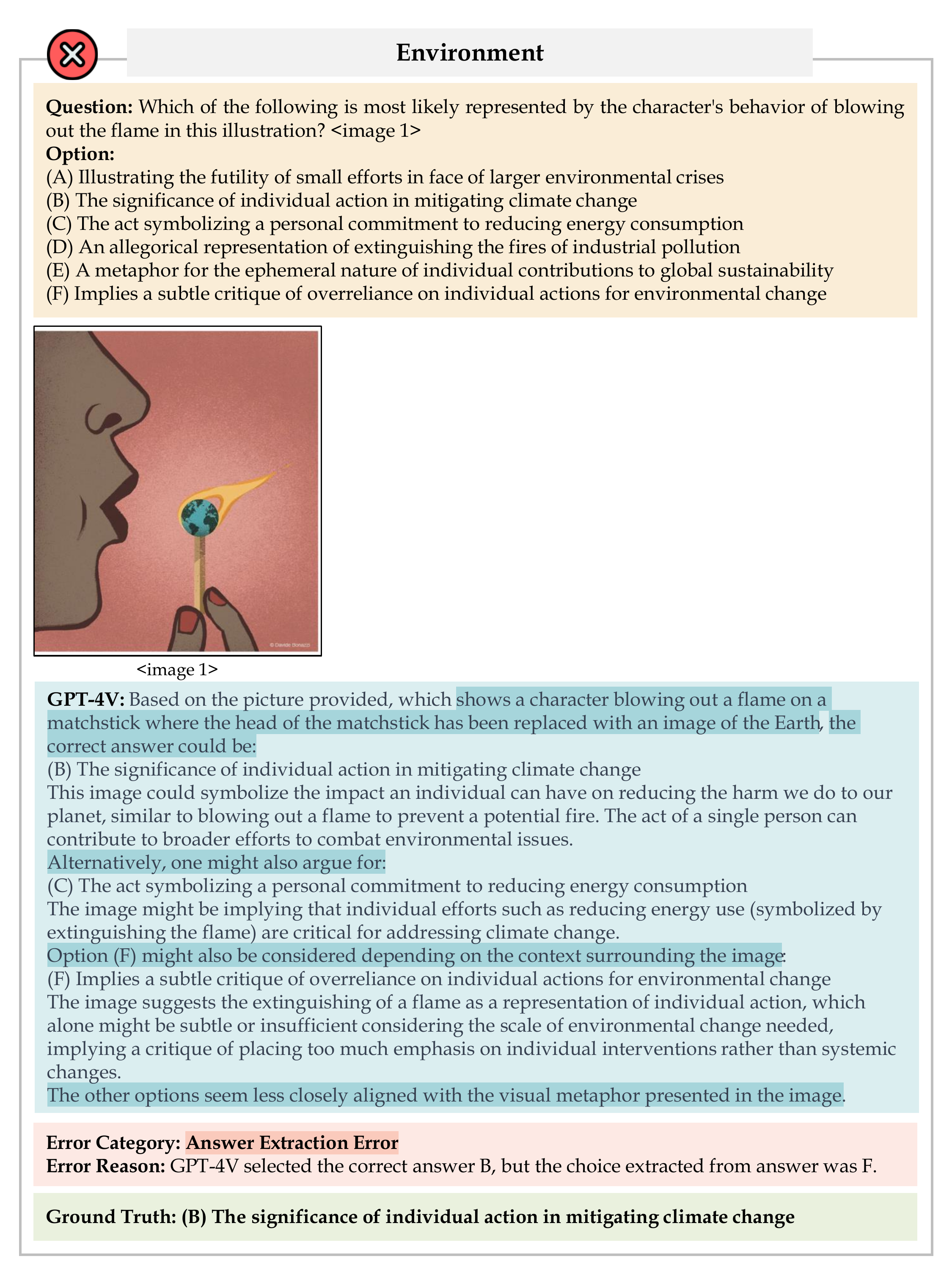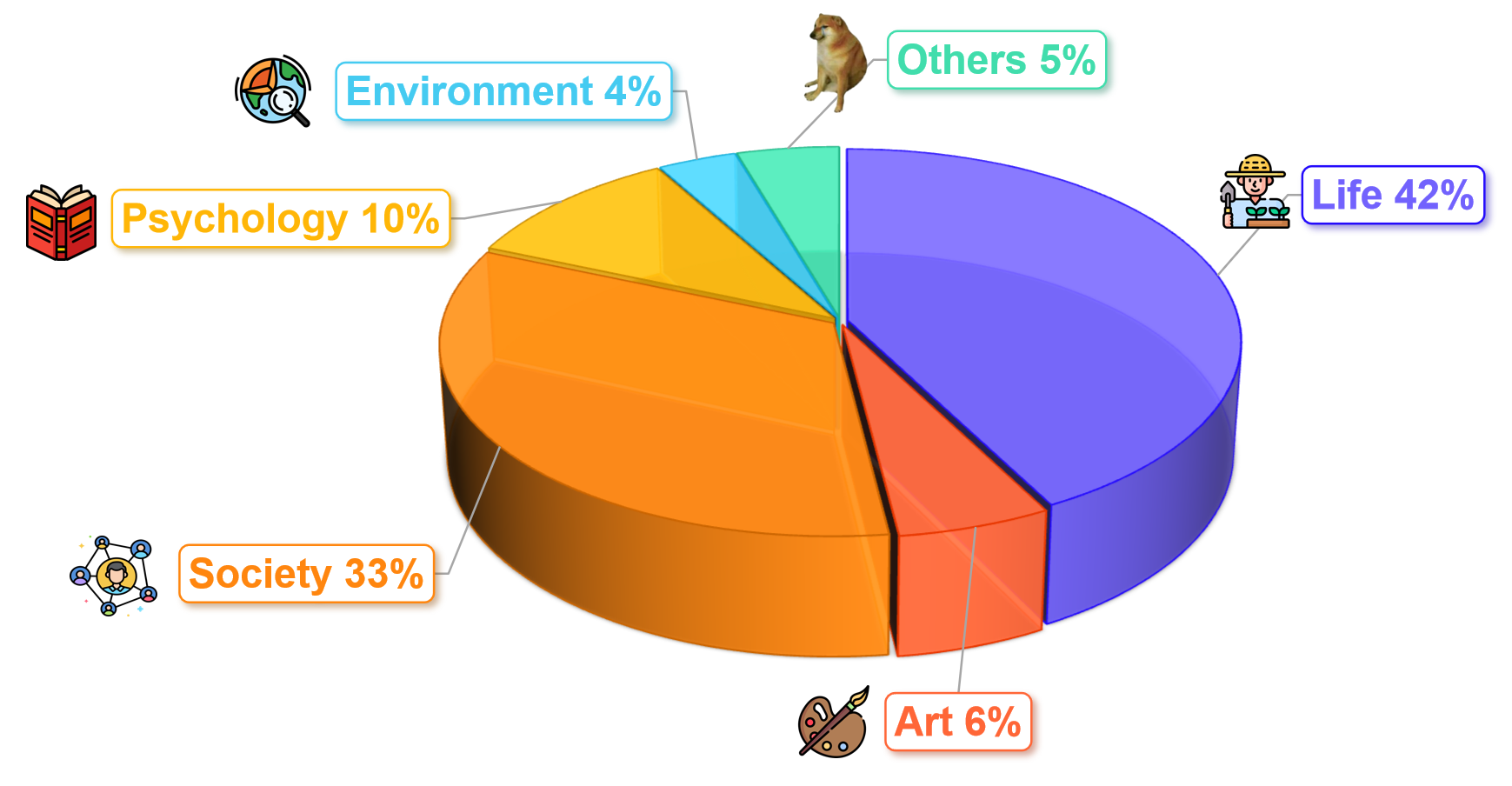

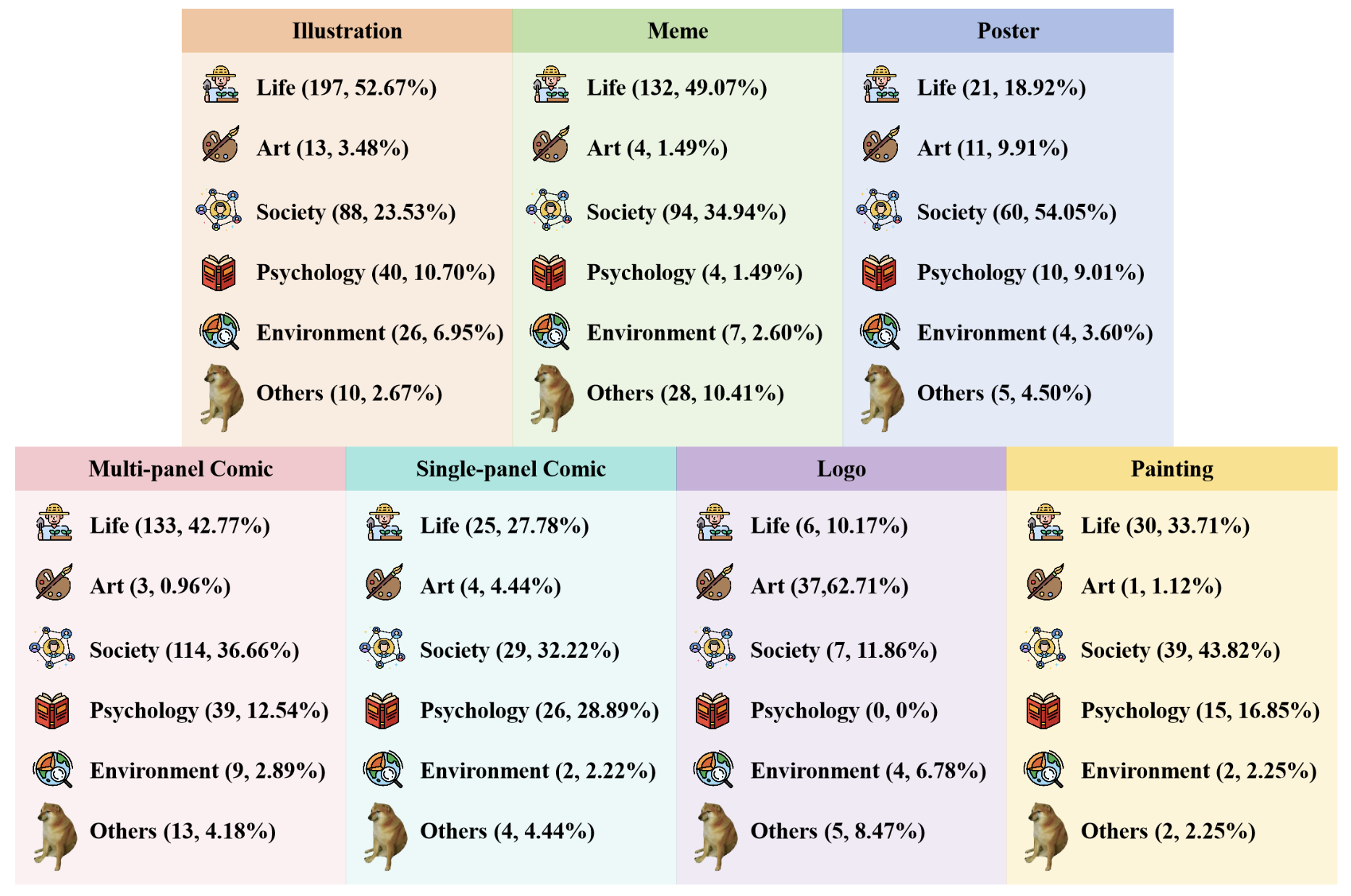
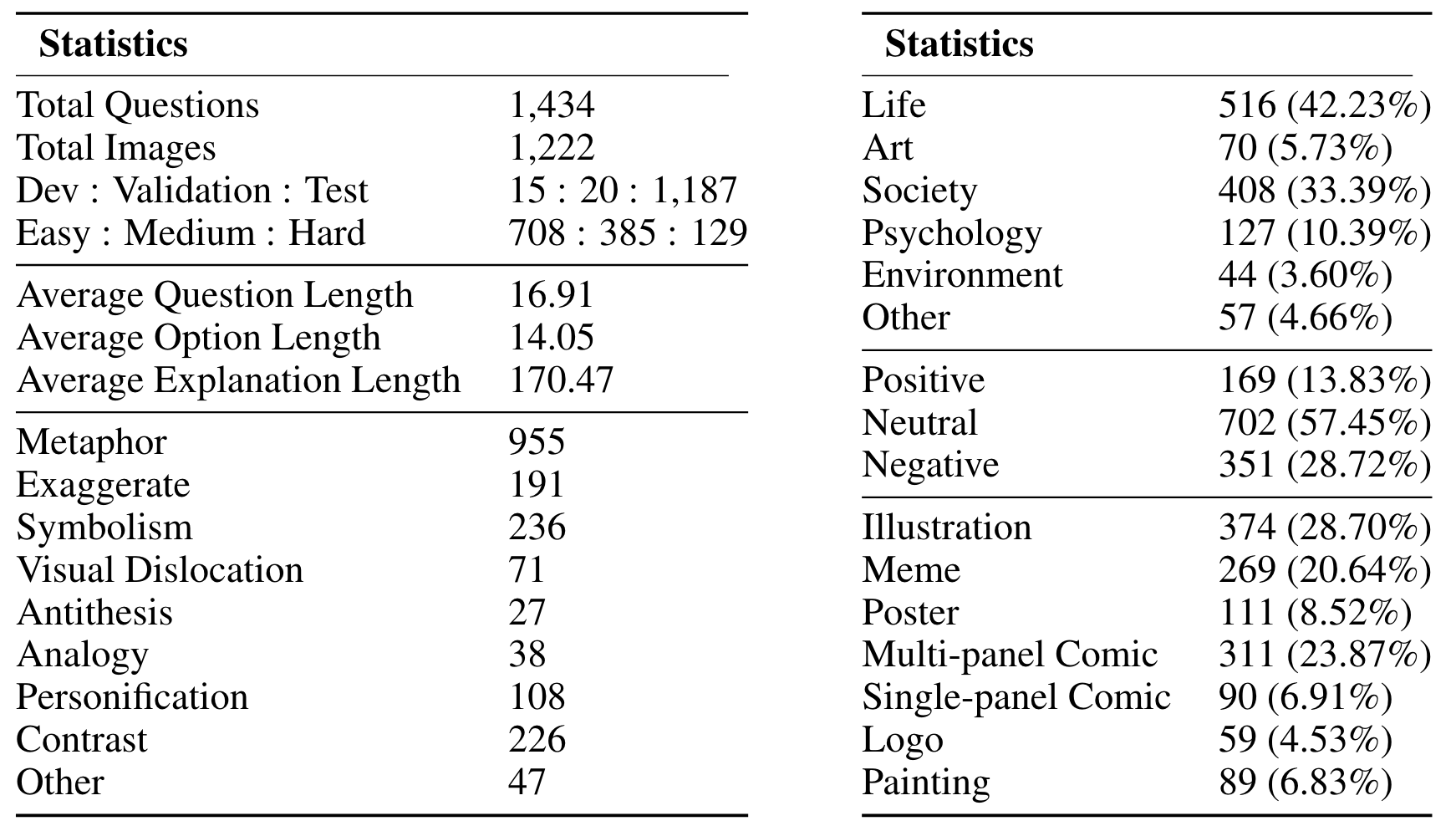
We conduct experiments on II-Bench using both open-source and closed-source MLLMs. For each model, we employ eight different settings: 1-shot, 2-shot, 3-shot, zero-shot (None), CoT, Domain, Emotion and Rhetoric. "Emotion" denotes prompts where the model is informed about the emotional polarity of the images(e.g., positive, negative), "Domain" involves adding information about the image’s domain (e.g., life, environment) to the prompt, and "Rhetoric" signifies prompt with information about the rhetorical devices used in the image (e.g., metaphor, personification), while "None" indicates the use of standard prompts without any additional information. Uniform prompts are applied across all MLLMs.
| Reset | Overall | Life | Art | Society | Psychology | Environment | Others | Positive | Neutral | Negative |
| Claude 3.5 sonnet | 80.9 | 81.4 | 77.6 | 80.9 | 78.3 | 86.3 | 83.1 | 81.1 | 80.9 | 80.9 |
| Qwen-VL-MAX | 74.8 | 74.7 | 71.8 | 74.6 | 73.0 | 76.5 | 84.6 | 80.1 | 74.5 | 72.9 |
| Gemini-1.5 Pro | 73.9 | 73.7 | 74.1 | 74.4 | 63.2 | 80.4 | 83.1 | 80.1 | 70.8 | 75.4 |
| GPT-4o | 72.6 | 72.5 | 72.9 | 73.3 | 68.4 | 76.5 | 75.4 | 78.6 | 71.2 | 72.5 |
| GPT-4V | 65.9 | 65.0 | 69.4 | 65.3 | 59.9 | 76.5 | 80.0 | 69.4 | 66.0 | 64.0 |
| LLaVA-1.6-34B | 73.8 | 73.8 | 71.8 | 73.3 | 71.1 | 78.4 | 81.5 | 79.1 | 72.9 | 72.9 |
| CogVLM2-Llama3-Chat | 70.3 | 68.9 | 68.2 | 70.9 | 67.8 | 72.5 | 86.2 | 69.9 | 71.1 | 69.1 |
| MiniCPM-Llama3-2.5 | 69.4 | 68.4 | 71.8 | 69.4 | 64.5 | 80.4 | 78.5 | 75.0 | 69.3 | 66.9 |
| Yi-VL-34B-Chat | 67.9 | 67.5 | 70.6 | 67.7 | 63.8 | 70.6 | 76.9 | 74.0 | 68.2 | 64.5 |
| Idefics2-8B | 67.7 | 67.2 | 74.1 | 67.7 | 62.5 | 74.5 | 70.8 | 68.9 | 67.0 | 68.4 |
| InternVL-Chat-1.5 | 66.3 | 63.6 | 65.9 | 68.5 | 65.8 | 64.7 | 76.9 | 73.5 | 65.4 | 64.5 |
| InternLM-XComposer2-VL | 62.1 | 61.7 | 62.4 | 62.3 | 58.6 | 70.6 | 66.2 | 65.8 | 63.0 | 58.7 |
| Yi-VL-6B-Chat | 61.3 | 60.9 | 63.5 | 60.7 | 56.6 | 66.7 | 72.3 | 61.7 | 61.7 | 61.1 |
| DeepSeek-VL-Chat-7B | 60.3 | 59.0 | 58.8 | 58.4 | 61.8 | 68.6 | 76.9 | 65.8 | 60.1 | 58.0 |
| BLIP-2 FLAN-T5-XXL | 57.8 | 57.1 | 63.5 | 57.0 | 53.3 | 66.7 | 66.2 | 67.9 | 57.2 | 54.3 |
| Mantis-8B-siglip-Llama3 | 57.5 | 56.8 | 61.2 | 57.5 | 53.9 | 64.7 | 61.5 | 59.2 | 58.0 | 55.6 |
| InstructBLIP-T5-XXL | 56.7 | 56.2 | 58.8 | 58.6 | 45.4 | 64.7 | 64.6 | 63.3 | 56.1 | 54.6 |
| Qwen-VL-Chat | 53.4 | 53.2 | 49.4 | 52.1 | 50.0 | 60.8 | 72.3 | 56.1 | 52.6 | 53.6 |
| mPLUGw-OWL2 | 53.2 | 54.0 | 56.5 | 50.5 | 52.0 | 60.8 | 56.9 | 55.6 | 52.6 | 53.1 |
| BLIP-2 FLAN-T5-XL | 52.8 | 53.0 | 58.8 | 52.5 | 42.8 | 64.7 | 58.5 | 56.1 | 52.9 | 51.0 |
| InstructBLIP-T5-XL | 47.3 | 45.6 | 48.2 | 48.8 | 44.7 | 52.9 | 50.8 | 46.9 | 48.3 | 45.4 |
| Human_avg | 90.3 | 90.0 | 88.2 | 91.4 | 86.6 | 96.1 | 92.3 | 84.7 | 89.1 | 92.2 |
| Human_best | 98.2 | 97.9 | 98.8 | 98.3 | 97.4 | 100.0 | 100.0 | 98.0 | 98.0 | 98.8 |
Overall results of different MLLMs and humans on different domains and emotions. The best-performing model in each category is in-bold, and the second best is underlined.